















Wykorzystanie naturalnych mechanizmów w nauce i technice to częste podejście. W ten sposób możemy rozwiązać złożone problemy i tworzyć innowacyjne rozwiązania. Poszukiwanie analogii do budowy ludzkiego mózgu doprowadziło do rozwinięcia niezwykle istotnych gałęzi sztucznej inteligencji. Czym są sztuczne sieci neuronowe i w jaki sposób mogą na przykład przetwarzać obrazy?
Zacznijmy od początku. Co to jest uczenie maszynowe?
Poszukując definicji uczenia maszynowego, możemy natknąć się na wiele wersji. Niezależnie od dokładnego sformułowania warto przede wszystkim zaznaczyć, że to bardzo ważna, a także bardzo obszerna dziedzina sztucznej inteligencji. To mechanizm coraz częściej wykorzystywany w różnych problemach – zarówno najbardziej zaawansowanych, jak i tych zupełnie przyziemnych.
Postaramy się zgromadzić kluczowe aspekty uczenia maszynowego w jednej definicji. Uczenie maszynowe (ang. machine learning) to technologia, której podstawowym założeniem jest dostarczenie pewnych danych komputerowi, który ma za zadanie znaleźć wśród nich pewne zależności. Następnie ta wiedza może być zastosowana w innych przypadkach, z którymi maszyna nie miała wcześniej do czynienia. To mechanizm bardzo podobny do tego, jak sami się uczymy. W ten sposób możemy rozwiązać nawet bardzo złożone zagadnienia, które dotąd były trudne (lub wręcz niemożliwe) do modelowania.
Uczenie maszynowe kontra klasyczne podejście

Czym wyróżnia się uczenie maszynowe na tle tradycyjnych technik programowania? Najistotniejszą różnicę można zauważyć już w samym podejściu do tworzenia programu. Algorytmy machine learning otrzymują na wejściu najczęściej zbiór danych wejściowych oraz przypisanych do nich odpowiedzi. Zadaniem programu jest samodzielna nauka i znalezienie wzoru, który będzie opisywał rozpatrywany problem. W przypadku programowania musimy w zasadzie podać wszystko „na tacy”, definiując konkretne zachowanie programu.
Uczenie maszynowe to bardzo ważna gałąź współczesnej informatyki, którą można wykorzystać na wiele sposobów. Znaczącą przewagą jest tutaj brak konieczności posiadania wiedzy o dokładnych zależnościach pomiędzy poszczególnymi czynnikami. Wystarczy odpowiednio duża ilość danych i już możemy przystąpić do działania. Obecnie techniki machine learning są powszechnie wykorzystywane między innymi do:
- filtrowania spamu na poczcie e-mail,
- rozpoznawania obiektów na zdjęciach,
- tłumaczenia maszynowego,
- personalizacji reklam internetowych,
- budowy autonomicznych pojazdów,
- przetwarzania obrazów.
Sztuczne sieci neuronowe – od biologii do informatyki
Sztuczne sieci neuronowe są uznawane za najskuteczniejsze narzędzia uczenia głębokiego, czyli jednej z technik uczenia maszynowego. Korzystając z ich możliwości, można stworzyć systemy czy aplikacje, które rozwiązują problem w sposób podobny do tego, który wykorzystałby człowiek. Sztuczne sieci neuronowe najczęściej stosuje się do rozwiązywania zadań takich jak rozpoznawanie obrazu, rozpoznawanie mowy czy tłumaczenie języków; ich zastosowanie może być jednak znacznie szersze. Wszystko zależy od ilości danych, którymi dysponuje użytkownik. Im więcej informacji otrzyma algorytm, tym lepiej będzie w stanie się nauczyć – dokładnie tak samo, jak ma to miejsce w rzeczywistym świecie.
Historia sztucznych sieci neuronowych sięga aż 1943 roku. Wtedy opracowano pierwszy model sztucznego neuronu, który mógł być wykorzystany do klasyfikacji obiektów do dwóch kategorii. Pod koniec lat 50. powstał perceptron Rosenblatta, czyli najprostsza sieć neuronowa. Jej możliwości były już o wiele większe, choć wciąż były bardzo odległe od tego, co współcześnie oferują nam tego typu narzędzia.
Architektura sztucznych sieci neuronowych
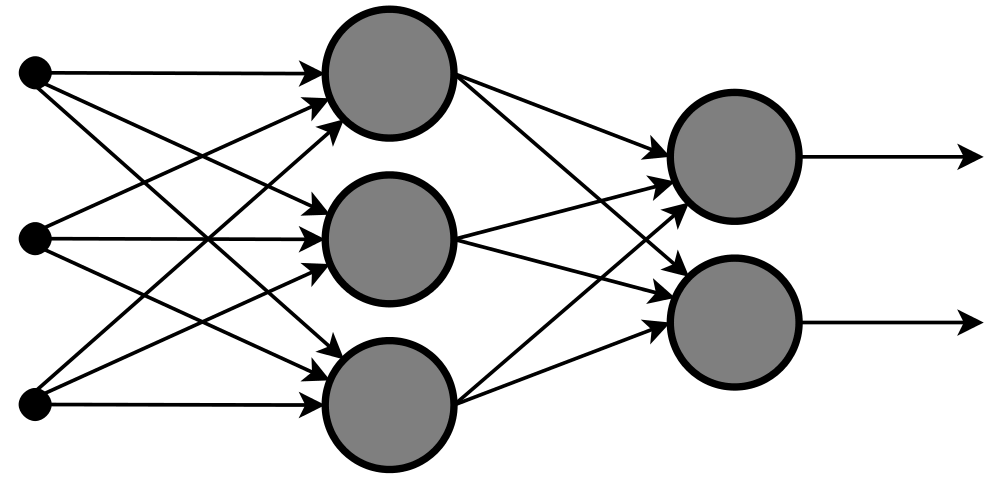
Sztuczne sieci neuronowe, podobnie jak mózgi zwierząt, są zbudowane z neuronów. Sztuczny neuron to podstawowa jednostka obliczeniowa, do której trafiają sygnały wejściowe, które są następnie odpowiednio przetwarzane. W większości modeli odpowiedź jednego neuronu stanowi wartość wejściową kolejnego, który na ogół znajduje się w następnej warstwie.
Sieci neuronowe mogą zawierać wiele warstw; istnieją także architektury, które podchodzą do tej kwestii w nieco inny sposób. W przypadku warstwowej budowy pierwsza część sieci odpowiada za gromadzenie informacji, a ostatnia – za zwracanie wartości. Pomiędzy nimi znajdują się tak zwane warstwy ukryte, które wykonują obliczenia i służą do uczenia sieci.
Wybór architektury danej sieci zależy przede wszystkim od zastosowania. Najczęściej bardziej złożona budowa pozwala dokładniej określić zależności, jednak nieodzownie łączy się z wydłużeniem obliczeń.
Uczenie głębokie, czyli jak sieci neuronowe zdobywają wiedzę

Uczenie głębokie stanowi jedną z klas algorytmów uczenia maszynowego, wykorzystującą złożone sieci neuronowe zbudowane z dużej liczby warstw i neuronów. Istnieje wiele strategii nauki sztucznych sieci neuronowych. Najbardziej ogólny podział wyróżnia uczenie nadzorowane, nienadzorowane i uczenie ze wzmocnieniem.
Pierwsze podejście zakłada ingerencję człowieka – program oprócz danych wejściowych otrzymuje przypisane do nich odpowiedzi. Jest to najprostszy rodzaj uczenia maszynowego, którego bardzo często używa się jest podczas analiz regresji i klasyfikacji. Uczenie nienadzorowane jest nieco trudniejsze; algorytm otrzymuje jedynie dane wejściowe bez przypisanych do nich etykiet. Ten rodzaj wykorzystuje się podczas klasteryzacji czy redukcji wymiarów. Najbardziej zaawansowanym i jednocześnie najtrudniejszym podtypem jest uczenie ze wzmocnieniem, którego działanie w głównej mierze opiera się na systemie „kar i nagród”.
Sztuczne sieci neuronowe w rozpoznawaniu obrazów

Uczenie głębokie z wykorzystaniem sztucznych sieci neuronowych bardzo często stosowane jest podczas przetwarzania obrazów. Jednym z najpopularniejszych rozwiązań jest zastosowanie konwolucyjnych sieci neuronowych do rozpoznawania obiektów. To technika, z którą mamy do czynienia na co dzień, choć często nawet nie zdajemy sobie z tego sprawy. Tego typu sieci stosuje się między innymi do rozpoznawania twarzy czy pisma, wspierania rozszerzonej rzeczywistości czy nawet przygotowywania diagnoz lekarskich.
Sztuczne sieci neuronowe oferują ogromne możliwości na wielu polach. Dodatkowo jest to dziedzina, która wciąż się rozwija. Zastosowanie bardziej złożonych algorytmów pozwala na rozwiązywanie kolejnych problemów z niemal każdego obszaru techniki czy codziennego życia.
Przetwarzanie obrazów za pomocą metod uczenia maszynowego staje się coraz bardziej zaawansowane. Możliwości sieci neuronowych to nie tylko rozpoznawanie prostych znaków. Są one w stanie rozpoznawać także twarze, tablice rejestracyjne, znaki drogowe oraz inne złożone obrazy. Ponadto istnieje możliwość klasyfikacji czy filtracji.
Konwolucyjne sieci neuronowe
Podczas przetwarzania obrazów za pomocą uczenia maszynowego najczęściej wykorzystuje się sieci konwolucyjne, które wyjątkowo dobrze radzą sobie w tym obszarze. Od innych architektur wyróżnia je umiejętność stopniowej filtracji różnych części danych oraz wyszczególnianie i wyostrzanie ważnych cech obrazu. Typowy model składa się z warstw filtrów i warstw sumowania, które kolejno przetwarzają dane o obrazie w postaci dwuwymiarowej matrycy pikseli. Kluczowym procesem jest tutaj tak zwana konwolucja. Jest to operacja matematyczna, która w skrócie polega na nałożeniu odpowiedniego filtru na dany sygnał.
Na czym polega konwolucja?
Poza samymi sieciami neuronowymi operację tego typu wykorzystuje się także w fotografii, muzyce i wielu różnych dziedzinach techniki. Wiele metod przetwarzania obrazów, na przykład rozmycie czy różnego rodzaju filtry, wykorzystuje właśnie konwolucję. W przypadku sieci neuronowych takie działanie służy do wykrycia charakterystycznych cech danego obrazu, by móc go precyzyjnie sklasyfikować.
Po nałożeniu odpowiedniego filtra sztuczna sieć neuronowa znajduje cechy istotne dla obrazu, a następnie je uwydatnia przed przekazaniem do kolejnej warstwy. W przypadku rozpoznawania znaków może to być dana litera, a w przypadku tablic rejestracyjnych – na przykład dany prostokąt. Zazwyczaj stosuje się wiele filtrów, z których każdy może odpowiadać za wyszczególnienie innej, konkretnej cechy.
Dlaczego jednak stosuje się takie podejście? Aby odpowiedzieć na pytanie, warto zastanowić się, jak w zasadzie przedstawić sam proces rozpoznawania obrazu. Załóżmy, że chcemy określić, czy na danym zdjęciu znajduje się kot. Dla człowieka jest to dość oczywiste – niezależnie od tego, czy znajduje się on na środku obrazu, czy w jego rogu. Możemy sprawnie określić rodzaj obserwowanego obiektu niezależnie od kontekstu. Niestety sztucznym sieciom neuronowym jeszcze trochę brakuje do naszej inteligencji; aktualnie klasyfikacja elementów różniących się jedynie położeniem wbrew pozorom nie jest prosta. Dzięki konwolucji obiekt nie jest zależny od położenia na obrazie, co pozwala uzyskać o wiele lepsze wyniki.
Dobieranie filtrów i ich modyfikacja to zadanie sieci neuronowej. Zazwyczaj na początek są one generowane losowo. Kolejne iteracje modyfikują ich działanie na zasadzie propagacji wstecznej, aby ostateczne rezultaty jak najbardziej zgadzały się z tymi oczekiwanymi przez użytkownika.
Budowa konwolucyjnej sieci neuronowej
W typowych sieciach konwolucyjnych można wytypować dwie podstawowe części. Pierwszą z nich jest tak zwana podsieć konwolucyjna, natomiast drugą standardowa, gęsto połączona sieć neuronowa. Pierwsza z nich odpowiada za nałożenie filtrów, a w kolejnej odbywa się właściwy proces nauki. Niekiedy stosuje się także warstwę łączącą (ang. pooling) pomiędzy poszczególnymi warstwami konwolucyjnymi. Do jej zadań należy stopniowe redukowanie wymiarowości, czyli liczby parametrów, co prowadzi do skrócenia czasu obliczeń. Inną bardzo ważną funkcją warstwy łączącej jest także kontrolowanie nauki i zapobieganie przeuczenia się sieci neuronowej. To niepożądane zjawisko, z którym mamy do czynienia najczęściej właśnie przy nadmiernym dopasowaniu parametrów – w efekcie model idealnie pasuje do danych uczących, jednak nie sprawdza się w ogólnym zastosowaniu.
Możliwości i zastosowanie
Konwolucyjne sieci neuronowe przyczyniły się do dynamicznego rozwoju uczenia maszynowego. To bardzo praktyczne narzędzie w kwestii możliwości przetwarzania obrazów. Wyniki pochodzące z klasycznych sieci neuronowych nie były zadowalające, ponieważ charakteryzowały się bardzo dużą wrażliwością na zmianę położenia obiektu. Procesy konwolucji zdołały niemal całkowicie wyeliminować ten problem.
Zastosowanie uczenia maszynowego w przetwarzaniu obrazów jest bardzo skuteczne. To podejście, które ma także spory potencjał – zwiększenie mocy obliczeniowej oraz gromadzenie większej ilości danych pozwoli dopracować obecne rozwiązania.








{kind=link}
{kind=link}